Recently streamer mokrivskiy announced event CIS Twitch Oscar 2020 (all in Russian and with Russian-speaking streamers), which includes multiple nominations, including a nomination called “Breakthrough of the year”. As far as I understood, Twitch viewers and streamers proposed nominees for the contest. Before the event I was thinking about how to classify Twitch channels into various categories, for example, rising stars, declining, stable. Category “Rising stars” and nomination “Breakthrough of the year” sound similar to me, so I looked at twelve nominees to see how growing Twitch channels look like. In this post I will try to jump in into an opportunity to analyse these channels and try to prioritize speed of analysis delivery over building data pipelines and managing infrastructure. The goal is to look at nominated channels through multiple angles such as hours streamed and viewed, followers, and viewers.
Data Preparation
Data that was collected from Twitch APIs with StreamSets Data Collector and with Python scripts was used as source data for this analysis. This data is not perfect and does not represent everything that ever happened on Twitch. We assume it is good enough to build a big picture.
Data quality dungeon
Source data is stored as a collection of gzip compressed json files. Within files JSON is stored as newline-delimited JSON or also called JSON Lines.
Used datasets were prepared with PySpark by removing duplicated records, selecting only relevant columns (for example, column “stream title” was not considered because it is free form text that requires extra analysis to make the column useful), integrating data that has different schemas.
Corrupted files
When I was loading all files with PySpark, it raised an error that something is wrong with the files.
(In Linux) Command gzip has switch -t that can be used to test whether the file is corrupted or not:
$ gzip -t streams_d887dec3-0ea4-4579-ab0f-e15be50baaf8_broken.json.gz
gzip: streams_d887dec3-0ea4-4579-ab0f-e15be50baaf8_broken.json.gz: unexpected end of file
Luckily, since files contain newline delimited JSON, I was able to recover data from the corrupted files that had more than one row by saving output of command zcat into a file and then deleting last row (which is incomplete).
Duplicated records
There were records that are complete duplicates that were saved within the same batch of API calls. This happened because Twitch API is paginated and there is a (variable several seconds) timeout between API calls. During a batch of API calls, some records moved from one page to the next one and were saved multiple times.
I considered records to be duplicated if they had exactly the same values within a 10 minutes interval (for example, between wall-clock minutes 10 and 19 inclusive). To achieve this, I had to truncate timestamp in column captured_at to beginning of 10 minutes interval.
Code to truncate timestamp to beginning of 10 minute interval in PySpark:
.withColumn('captured_at_interval', F.date_trunc('hour', F.col('captured_at')) + F.floor(F.minute(F.col('captured_at')).cast('Int') / 10) * F.expr('INTERVAL 10 minutes'))
Then duplicated records were removed in PySpark by using function .drop_duplicates(subset=['captured_at_interval', 'another_column_name']), which supports argument subset that can be used to provide a column or a list of columns that define a unique record.
Different schemas
Over time schema for files changed.
For example, files that were produced by StreamSets Data collector have timestamp represented as unix timestamp, while newer python scripts saved timestamps in ISO 8601.
This was solved by using when functions (same as CASE statements) in PySpark and casting fields with timestamps to data type timestamp.
Another problem that for one endpoint schema changed from flattened and renamed fields to original JSON with nested fields. This was easily solved with PySpark, because it has an ability to merge different schemas. After PySpark merged those files into a common schema, functions when and coalesce were used to merge columns into new schema.
Technology
ClickHouse
ClickHouse natively supports import of Parquet files (and many other formats). I wanted to be smart and use GNU Parallel to load files into ClickHouse, but this resulted in an error:
Code: 33. DB::ParsingException: Error while reading Parquet data: IOError: Unexpected end of stream: Page was smaller (30902) than expected (31182): data for INSERT was parsed from stdin
Files were successfully loaded sequentially in a loop (like in the article Faster ClickHouse Imports):
for FILENAME in *.parquet; do cat $FILENAME | docker run -i --rm --network rill_analytics_rill_net yandex/clickhouse-client --host clickh --query="INSERT INTO rill.twitch_streams FORMAT Parquet"; done
At some point I have also copied data from TimescaleDB Docker instance into ClickHouse Docker instance:
psql --host 127.0.0.1 --port 5433 -U jastix rill -c "COPY (SELECT * FROM rill.streams) TO STDOUT WITH (FORMAT CSV, FORCE_QUOTE *)"
| docker run -i --rm --network rill_analytics_rill_net yandex/clickhouse-client --host clickh --query="INSERT INTO rill.twitch_streams FORMAT CSV"
Here I have learned FORCE_QUOTE option for psql that forces quoting for non-NULL values, otherwise ClickHouse raised errors when ingesting this CSV data.
Execution speed is not an issue for ClickHouse. Partial support for SQL is a bigger issue, especially lack of support for Window functions (as of February 2021 they are in development). This resulted in constant searching for workarounds and questioning whether I am writing correct SQL. There is no official Docker container available on Docker Hub for ARM architecture, which prevented me from running ClickHouse easily on Raspberry PI.
TimescaleDB
PostgreSQL was considered an alternative solution to host data for analysis and as a backend for visualizations, because it is widely supported by visualization software and it has powerful SQL support. Since source data is a time series data, I have used TimescaleDB since it is promoted as a database that is optimized for time-series data.
PostgreSQL includes COPY command to efficiently load data into the database. Big drawback of that command that it only understands tab-delimited data or CSV.
The first idea was to load data into a JSONB column and then do processing in the database (ELT way). Since PostgreSQL does not directly support loading of JSON, it was problematic to load the data using COPY command, because there are text fields that contain all kinds of values that should be escaped and this leads to preprocessing of data before loading data into the database. For example, this problem:
find $PWD -name "*.gz" | parallel 'zcat {}' | psql --host 127.0.0.1 --port 5433 -U jastix -d rill -c "COPY twitch.v5_top_games(content) FROM STDIN;"
ERROR: invalid input syntax for type json
DETAIL: Expected end of input, but found "{".
CONTEXT: JSON data, line 1: ...rs":25,"channels":5,"captured_at":1590161422000}{...
COPY v5_top_games, line 899, column content: "{"game_name":"Ark: Survival Of The Fittest","game__id":491873,"game_giantbomb_id":59395,"game_locali..."
I decided to not fight with PostgreSQL COPY and use PySpark to pre-process files and produce CSV files that are suitable for loading into PostgreSQL.
To ingest CSV files I have used meta-command \copy in psql:
rill=# \copy rill.streams(captured_at,game_id,game_name,id,language,started_at,user_id,user_name,viewer_count) from 'part-00002-8af665c2-d580-4002-a8c9-41371822783b-c000.csv' WITH (FORMAT CSV, HEADER, ESCAPE '\', FORCE_NULL('game_id'));
I have learned that attribute HEADER does not help with mapping of CSV columns to PostgreSQL table columns, but only instructs PostgreSQL to ignore first line. Another useful option is FORCE_NULL, which helped to overcome a problem when empty string was in the column that is of data type BIGINT: ERROR: invalid input syntax for type bigint: “”.
I took definition of column names from actual CSV files using head.
Compression
Out of interest I have compared sizes between uncompressed CSV file, PostgreSQL table, Compressed TimescaledDB hypertable, and ClickHouse table for streams dataset.
Table schema:
CREATE TABLE IF NOT EXISTS rill.streams (
captured_at TIMESTAMP,
game_id BIGINT,
game_name TEXT,
id BIGINT NOT NULL,
language TEXT,
started_at TIMESTAMP,
user_id BIGINT NOT NULL,
user_name TEXT,
viewer_count BIGINT NOT NULL
);
Number of records: 143_106_788
- CSV file size: 13 GB
- PostgreSQL table size: 21 GB
- TimescaleDB compressed table: 3 GB
- ClickHouse table size: 842.37 MiB
For ClickHouse, MergeTree engine was used with no extra tweaks with compression codecs. For both TimescaleDB and ClickHouse the table was sorted such that the same values are stored next to each other.
In ClickHouse the table was sorted as ORDER BY (user_id, id, captured_at) and in TimescaleDB the table was setup with segmentby = user_id and orderby = id, captured_at
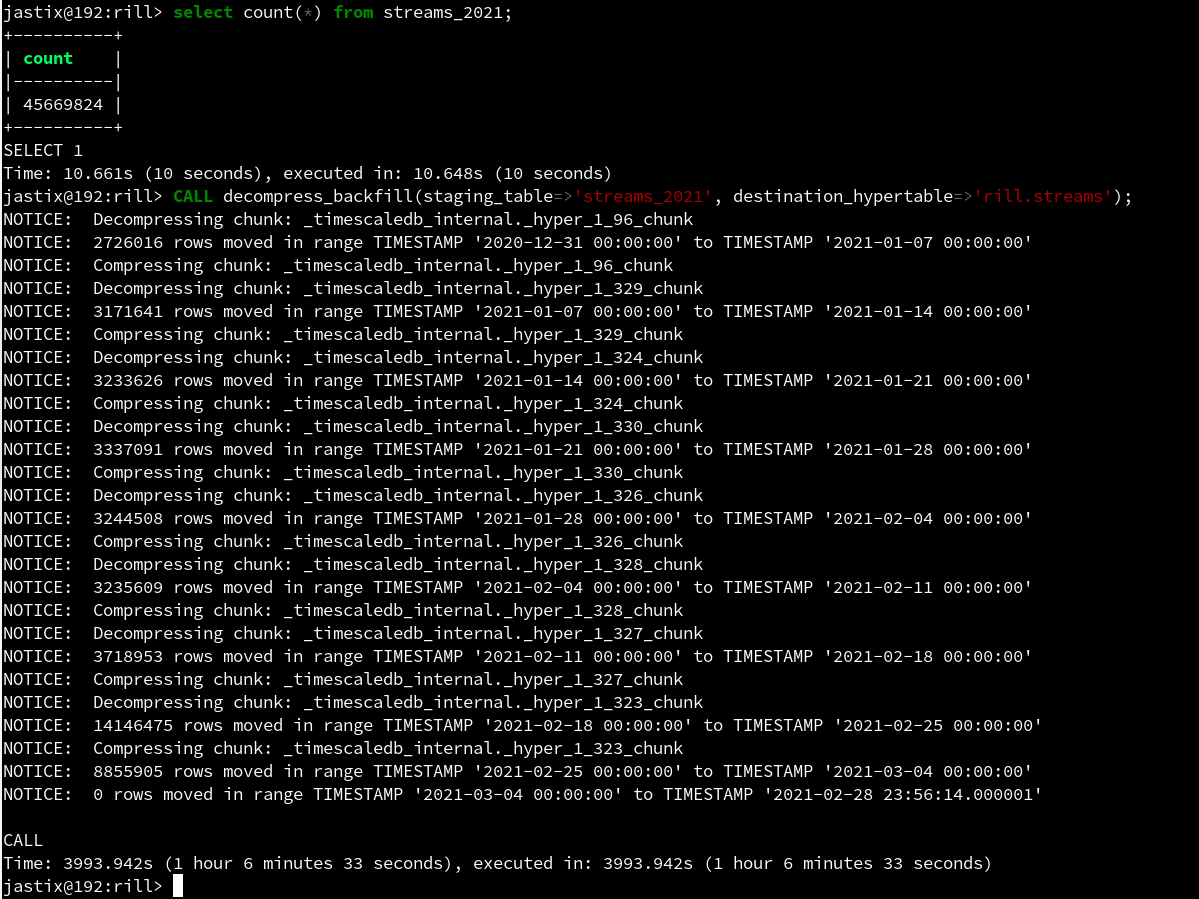
Backfilling data in TimescaleDB
After setting up hypertables with compression in TimescaleDB, I have decided to add more data to the table. Currently (February 2021) TimescaleDB does not support inserts and updates for compressed tables. In order to overcome this limitation, TimescaleDB documentation contains instructions on how to backfill new data and provides code to achieve this.
I have made use of that code and added new data into the compressed table. On Raspberry PI 4 8 GB it took 1 hour 6 minutes to backfill 45_669_824 rows into the table with 143_106_788 records (this increased TimescaleDB table size to 4 GB).
Apache Superset and Redash
For visualization Apache Superset and Redash were considered because they support ClickHouse as backend. Apache Superset was much easier to add to existing Docker Compose file, while I had to spend more time looking at Redash setup scripts. In terms of productivity, in Redash I could build desired charts faster than with Apache Superset. For this reason, Redash is used for visualizations here.
The nominees
Twelve channels were nominated for “breakthrough of the year” and we will do a first look at them in terms of channel names, channel age (on 01/02/2020), partnership status, team affiliation, and their follower count growth.
The oldest channel is ZLOYn that was created on 06/06/2011 and it was 8 years 7 months old on 01/02/2020.
The youngest channel is ekatze007 that was only 3 months old in the beginning of 2020.
Other channels have various ages of 1, 2, 3, 4, and 6 years.
In terms of partnership status, 10 out of 12 channels were Twitch partners at the end of 2020. Out of 10 partners: 6 were already partners before 2020, while the other 4 became partners during 2020. Only channel mokrivskyi was never a partner and channel PCH3LK1N lost partnership status during 2020.
Columns min_captured_at and max_captured_at show earliest and latest (until February 2021) collected events timestamps, respectively. Only January and February 2020 were considered as the beginning of the year.
+----------------+------------------------+----------------------+------------------------------+----------------------------+---------------------+---------------------+
| channel_name | followers_begin_2020 | followers_end_2020 | partnership_status | channel_age | min_captured_at | max_captured_at |
|----------------+------------------------+----------------------+------------------------------+----------------------------+---------------------+---------------------|
| karavay46 | 87978 | 451918 | Partner before 2020 | 02 Years 04 Months 05 Days | 2020-01-24 18:41:29 | 2021-01-30 13:25:02 |
| ZLOYn | 21045 | 431693 | Partner before 2020 | 08 Years 07 Months 24 Days | 2020-01-24 11:53:55 | 2021-01-31 13:25:01 |
| mokrivskyi | 14545 | 395699 | Never partner | 04 Years 06 Months 00 Days | 2020-01-24 14:54:07 | 2021-01-31 13:25:01 |
| StRoGo | 27167 | 385590 | Partner before 2020 | 01 Years 07 Months 06 Days | 2020-01-24 11:42:52 | 2021-01-31 19:25:02 |
| dinablin | 59967 | 384433 | Partner before 2020 | 03 Years 09 Months 25 Days | 2020-01-24 17:14:23 | 2021-01-30 15:25:02 |
| PCH3LK1N | 76309 | 329243 | Lost partnership during 2020 | 06 Years 04 Months 16 Days | 2020-01-24 09:48:39 | 2021-01-31 13:25:01 |
| ekatze007 | <null> | 306561 | Partner during 2020 | 00 Years 03 Months 22 Days | 2020-10-04 20:25:01 | 2021-01-31 22:25:01 |
| pokanoname | 4979 | 257331 | Partner during 2020 | 02 Years 07 Months 18 Days | 2020-01-24 19:45:16 | 2021-01-31 20:25:01 |
| JojoHF | 4732 | 255975 | Partner before 2020 | 02 Years 09 Months 29 Days | 2020-02-05 12:00:05 | 2021-01-28 14:25:01 |
| Mapke | 37727 | 231211 | Partner before 2020 | 01 Years 11 Months 08 Days | 2020-01-25 13:54:33 | 2021-01-17 22:25:02 |
| GAECHKATM | 1851 | 182049 | Partner during 2020 | 00 Years 06 Months 09 Days | 2020-01-26 01:04:39 | 2021-01-30 12:25:01 |
| VERNI_SHAVERMY | 2649 | 127871 | Partner during 2020 | 03 Years 04 Months 14 Days | 2020-01-24 19:44:29 | 2021-01-31 23:25:01 |
+----------------+------------------------+----------------------+------------------------------+----------------------------+---------------------+---------------------+
Followers count increased for all channels with PCH3LK1N had the lowest percentage increase of 331% (although this channel had second biggest number of followers in the beginning of 2020) and GAECHKATM had the highest percentage increase of 9735%, while being the second youngest channel.
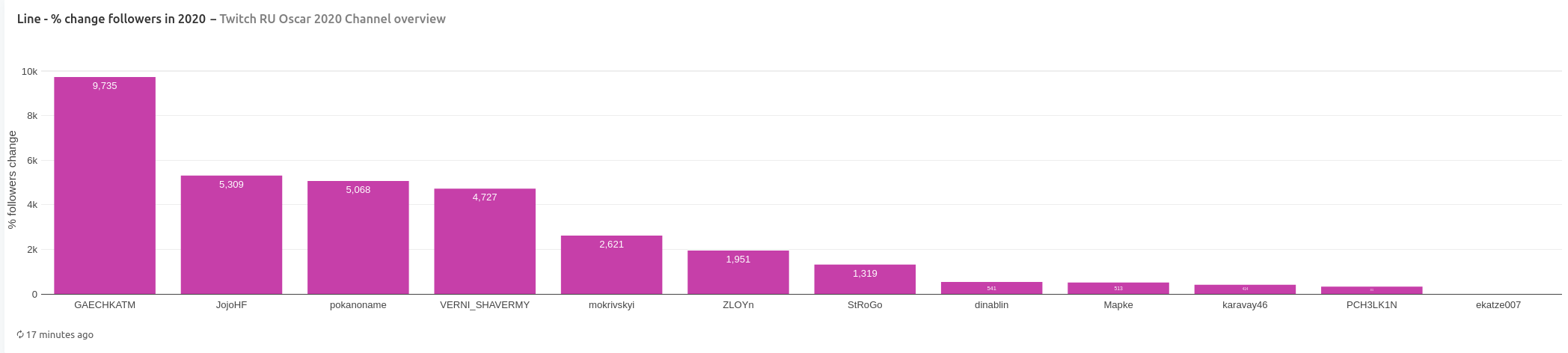
In terms of team affiliation, all but one channel were part of some Twitch team by the end of January 2021. Team FREAK has the biggest representation among nominated channels.
(channel name): (teams)
dinablin: FREAK
VERNI_SHAVERMY: (no team)
karavay46: Streamers Alliance, FREAK, ПУЗАТА ХАТА (89freaksquad)
GAECHKATM: 89SQUAD, ПУЗАТА ХАТА (89freaksquad)
mokrivskyi: FREAK
PCH3LK1N: FREAK
JojoHF: ПУЗАТА ХАТА (89freaksquad)
pokanoname: FREAK
ekatze007: FREAK
Mapke: FREAK
ZLOYn: 105TV, FREAK
StRoGo: FREAK
Exploration
For purposes of exploration, time interval for data is defined as from 1st February 2020 up to 1st February 2021 (exclusive), because public voting took place in February 2021.
Viewers
The first thing that comes to mind when talking about online streaming is how many people actually viewed the streams. To compare channels in terms of viewers, we will compute a median number of viewers per month for each channel.
I compute median instead of average to remove effect of raids (when one channel redirects its viewers to another channel). Median will show lower number of viewers, but more realistic. Comparison of average and median viewer count for one stream:
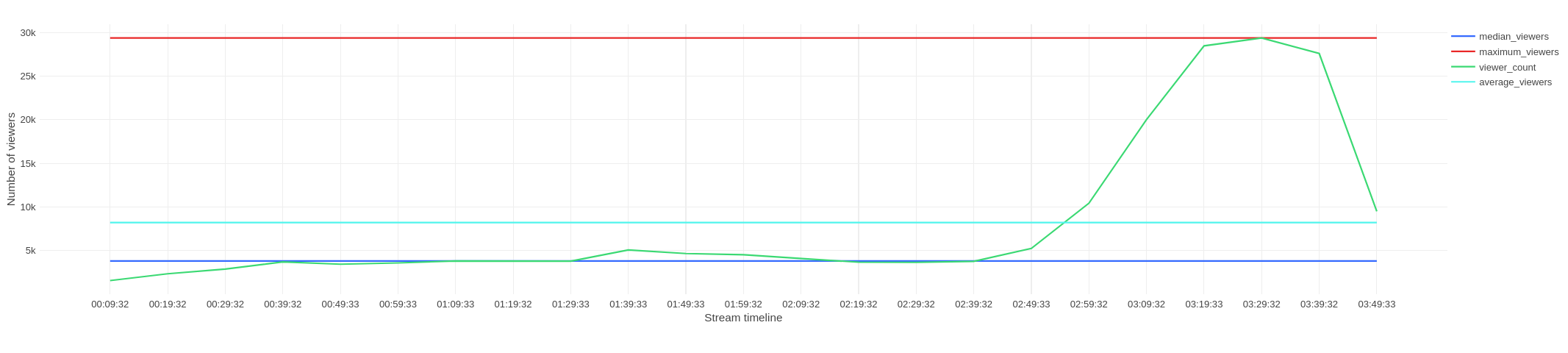
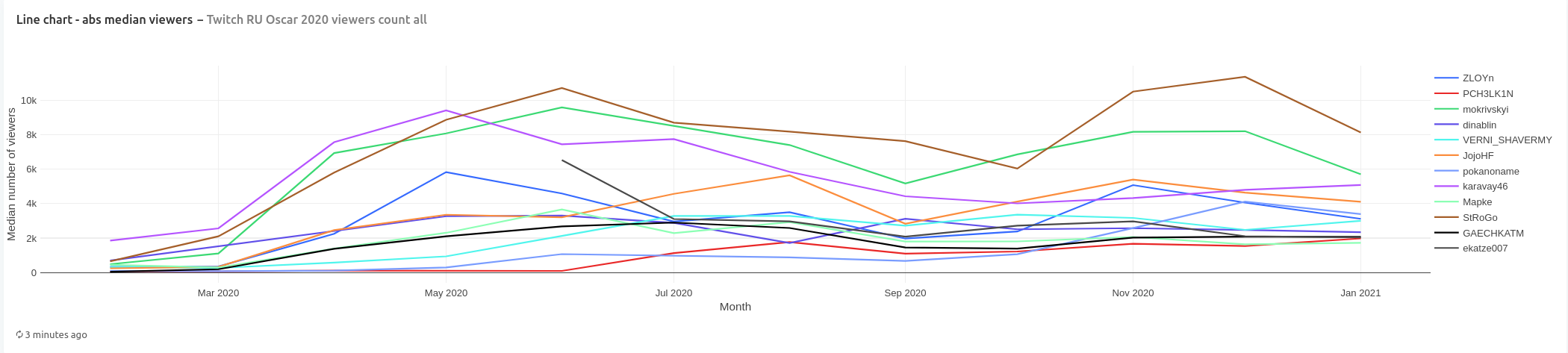
Chart with median number of viewers per month per channel shows that in the first half of the year channels karavay46, StRoGo, and mokrivskyi had higher median count of viewers than the rest with dividing line somewhere at between 6000 and 7000 viewers. By the end of the year no other channels managed to achieve this viewer count and karavay46 joined channels with under 6000 viewers, because its viewer count declined.
Calculation of percent change of median viewer count between February 2020 and February 2021, shows that channels GAECHKATM and pokanoname showed the biggest growth of 4941% and 3802% respectively, with channel PCH3LK1N at the third position with growth of 3310%. The rest of the channels had less than 2000% growth.
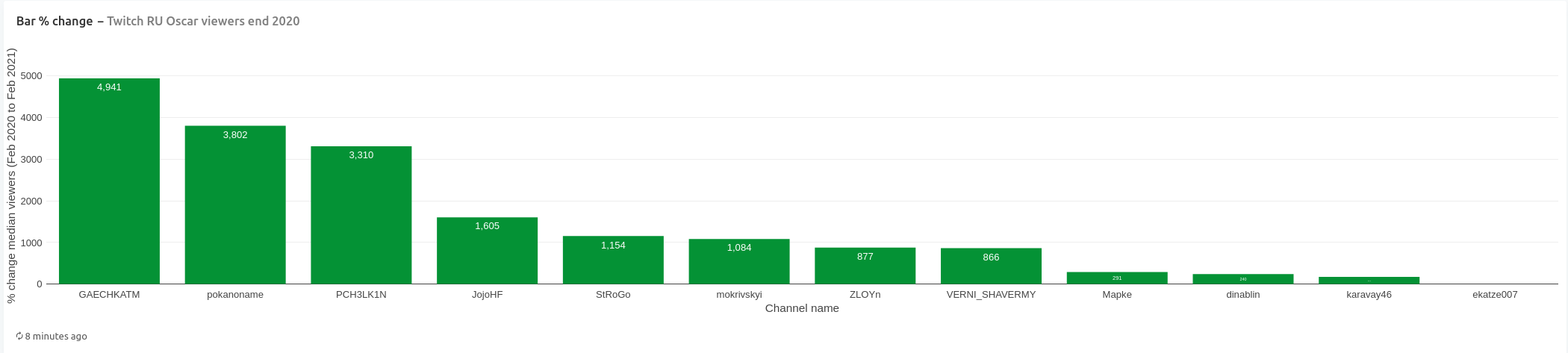
Looking at month over month change in number of viewers, we see all channels showed noticeable growth in the beginning of 2020 (with JojoHF and GAECHKATM leading). Channel pokanoname shows highest growth in June compared to other channels, while channel PCH3LK1N is flying high in July 2020 with highest ever month over month growth of 1138%
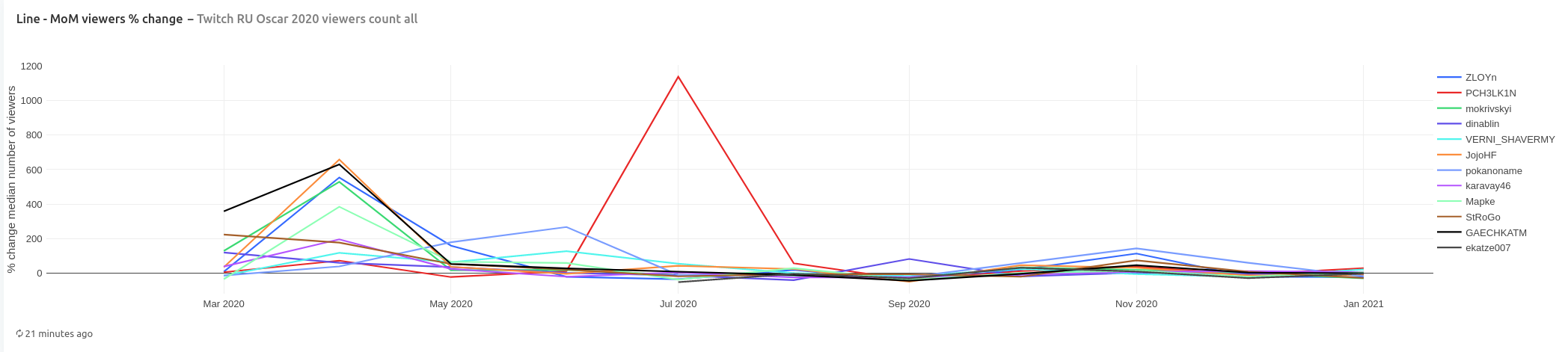
In terms of viewers, channel GAECHKATM is leading again with highest percentage growth of viewers in 2020, while channels StRoGo and mokrivskyi show highest number of median number of viewers monthly.
Hours
Next set of computed indicators shows the number of hours streamed and number of hours watched. Number of hours streamed is the sum of all hours when the channel was live (such broadcasts as re-runs were not considered).
Number of hours viewed is calculated as segment duration multiplied by average viewer count in this segment. The source data represents a stream as a set of measurements that were taken at various intervals (usually about 10 minutes). Average viewer count is calculated as average viewer count between beginning and end of a segment.
In terms of total hours watched, channels mokrivskyi, VERNI_SHAVERMY, StRoGo are leading and again nominees are divided into two groups. One group that had over 3 million hours watched (6 channels) and the other group with channels that had less than 2 million hours watched (6 channels).
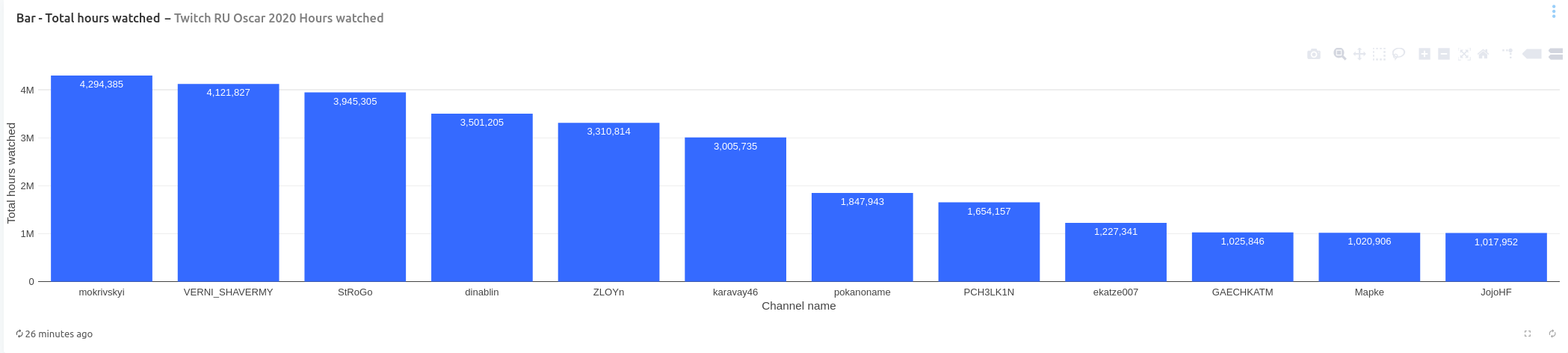
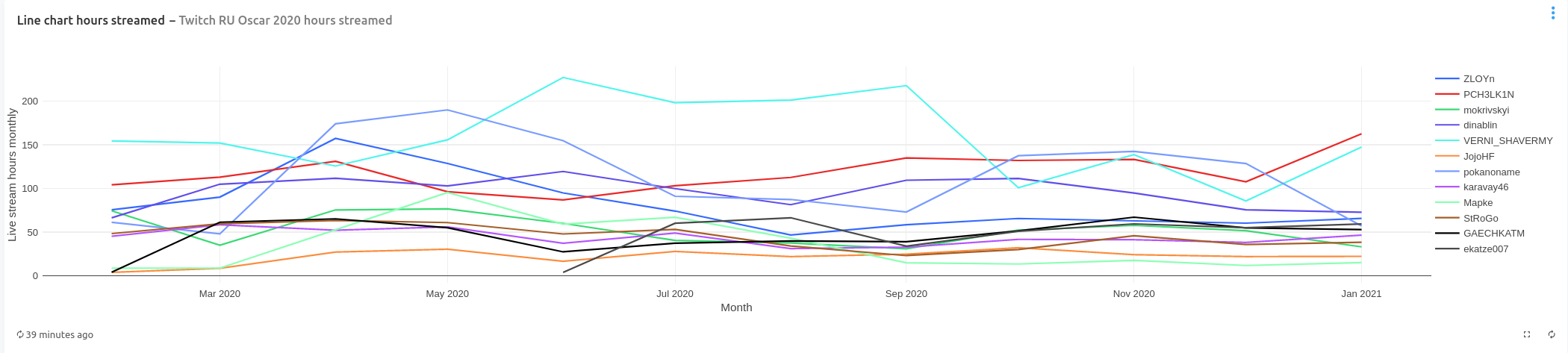
Channel VERNI_SHAVERMY streamed the most hours in 2020 with 1904 hours live. It is followed by channels PCH3LK1N and pokanoname that are close together with 1415 and 1321 hours, respectively. Here channels are divided into two groups: one group that streamed over 900 hours and the other group that streamed less than 700 hours.
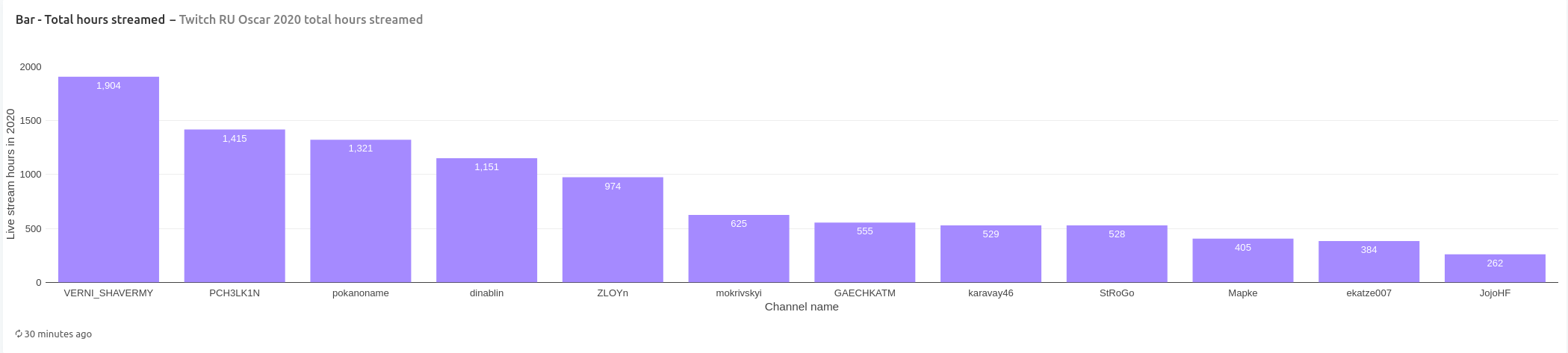
Breaking down hours streamed by month, we see that channel VERNI_SHAVERMY streamed the most hours in the beginning of the year and during summer months (peaking at 227 hours streamed in June), but streamed fewer hours towards the end of the year. This is also more hours streamed than a typical full-time work hours per month (160 hours).
Since august 2020 channels can be divided into two groups: one groups that streamed over 70 hours monthly (which are only four channels: VERNI_SHAVERMY, pokanoname, dinablin, PCH3LK1N) and all others that streamed less than 70 hours.
Categories
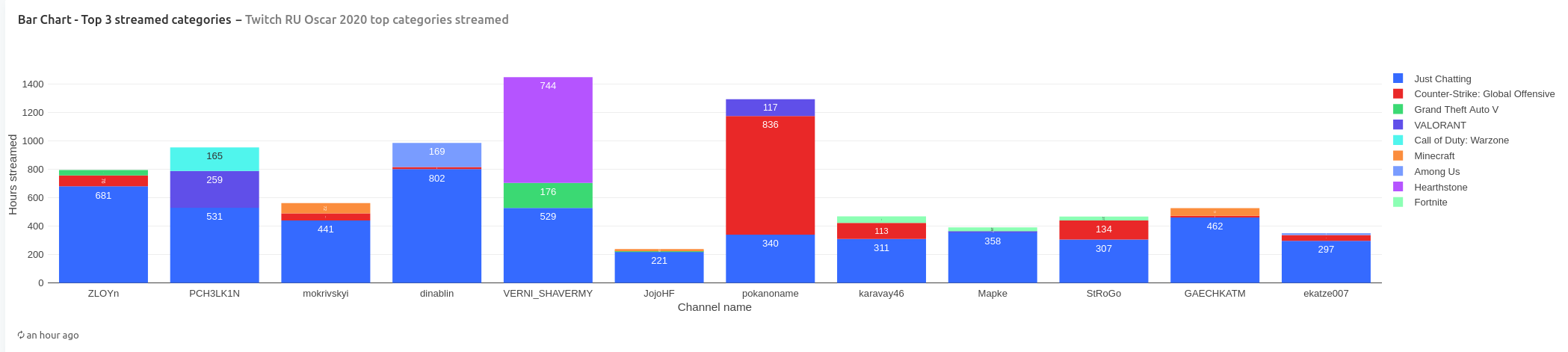
Finally, we look at top 3 categories that were streamed by the nominees in terms of number of hours live.
Most channels (10 out of 12) spent most of their streaming hours in category “Just Chatting”. Only channels VERNI_SHAVERMY and pokanoname spent most of their streaming hours in gaming categories: “Hearthstone” and “Counter-Strike”. Notably, channel PCH3LK1N is reaching about 50:50 ratio between gaming and non-gaming categories in top-3.
Summary
I have jumped in into the opportunity to use collected data from Twitch API to calculate some metrics for nominees for CIS Twitch Oscar 2020. In order to have data prepared for (easier) querying for analytical purposes, I have transformed data from JSON stored in gzip compressed files using PySpark (this transformation was executed multiple times because of data quality issues).
For the analytical database, ClickHouse was the first choice, and it narrowed down choice of visualization tools to Apache Superset and Redash. Spark with Hive were not selected, because this setup would require at least two systems to be running (Apache Spark and Apache Hive) instead of one system in case of ClickHouse or PostgreSQL. Eventually, ClickHouse was replaced by TimescaleDB, because ClickHouse does not support window functions and it was taking time to figure out workarounds. TimescaleDB provided the same SQL support as PostgreSQL, plus the ability to transform table storage into columnar format. TimescaleDB was deployed to Raspberry PI 4 8 GB and provided unexpectedly good performance (dashboard queries took up to 5 seconds to execute).
For visualizations, Redash was used because initial productivity was higher than with Apache Superset. Although, it was more difficult to incorporate Redash into existing Docker Compose stack.
This infrastructure and prepared data enabled us to compute metrics for 12 Twitch channels that were nominated as “breakthrough of the year”.
The first thing we saw is that nominated channels are not necessarily recently created on Twitch, as their age ranged from being several months old to 8 years old.
In terms of content type, most channels (10 out of 12) primarily stream in category “Just Chatting”. While the other two channels played a lot of Hearthstone and Counter-Strike: Global Offensive.
When it comes to growth, channel GAECHATM was leading in metrics of percentage followers change and percentage median viewers change. But the same channel did not show the same significant results in another metrics, such as Hours watched (for the entire period and monthly) or Hours streamed.
Channel VERNI_SHAVERMY streamed the most hours in between February 2020 and January 2021, and was #2 channel with most hours watched. Notably, this channel streamed more hours monthly than a typical full-time work during summer months in 2020.
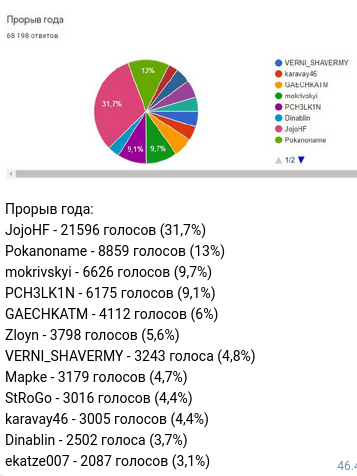
My guess was that channels GAECHATM and VERNI_SHAVERMY are great candidates to win this nomination. The results were announced on 1st March 2021 and channel JojoHF won this nomination (with 31,7% of all votes). That was unexpected.
Used hardware:
PySpark (3.0.1), ClickHouse, Redash (8.0.0+b32245): Core i7-6700HQ, 32GB RAM DDR4 2133, Samsung SSD 860 EVO 1TB.
TimescaleDB (2.0.2, 2.1.0): Raspberry PI 4 8 GB with Toshiba NVME drive connected via USB (enclosure based on chipset RTL9210B).