In the previous post we have explored Twitch API using Elixir programming language. We have done our exploration in order to plan how to build a process that acquires data from Twitch API. Data acquisition problem is a common problem in Data analysis and Business intelligence. In data warehousing there is a process called ETL (Extract, Transform, Load), which represents how data flows from source systems to destinations. One way to acquire data is to write custom code for each source (bringing challenges of maintenance, flexibility, reliability). The other way is to use one of systems that were built to solve the data acquisition problem.
StreamSets Data Collector
One of the more modern systems for data acquisition is StreamSets Data Collector (or SDC).
SDC contains connectors to many systems that act as origins or destinations. Those systems include not only traditional systems such as relational databases,
files on a local file system, FTP, but also more modern ones such as Kafka, HDFS, cloud tools (e.g., Amazon S3, Google BigQuery, Microsoft Azure HDInsight).
Another feature of SDC is graphical user interface for building data pipelines from predefined blocks, which are called stages, and they are divided into four categories:
- Origins (stages that define from where and how to acquire data);
- Processors (stages to transform data);
- Destinations (stages that define where data will be saved);
- Executors (stages that define that some task should be triggered).
Stages are described in details in SDC documentation.
Building Data Pipelines with SDC
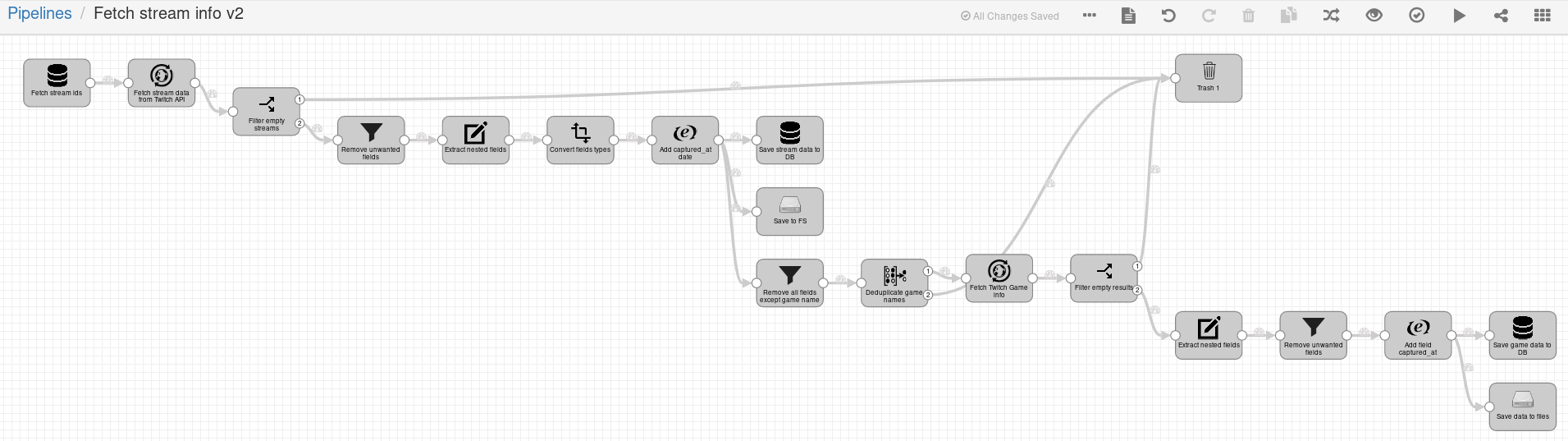
We will build data pipelines to acquire data about streams and games on Twitch. The process to obtain data about streams and games looks like this:
- Find user’s username (e.g., from a Twitch URL);
- Make a request to Twitch API to convert username to stream id;
- Make a request to Twitch API (using stream_id) to obtain data about user’s stream (is there a live steam, is there a recording being played);
- Make a request to Twitch API (using game name) to acquire data about game’s stats on Twitch (how many viewers in total for this game);
- Make a request to Giantbomb API (using giantbomb_id) to acquire data about a particular game (genre and release date)
Converting user name to stream_id
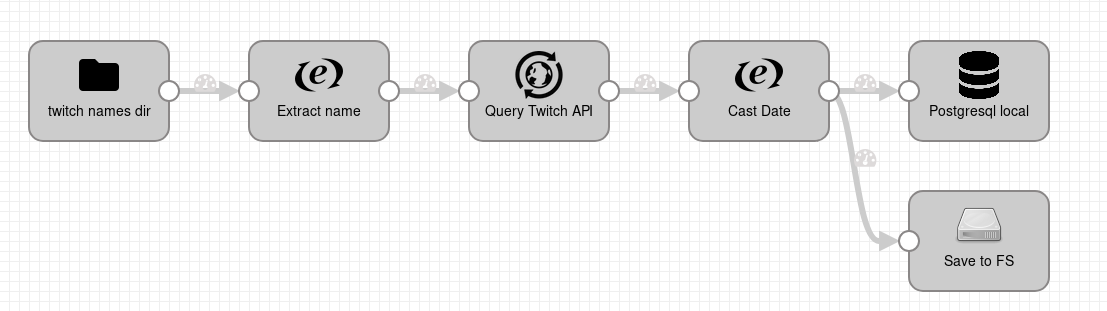
Figure. Twitch name to stream_id pipeline
First data pipeline was built to convert user names to stream ids. Data pipeline starts by watching a directory for new text files.
Names of text files correspond to user names and contain one line with a user name.
SDC pipeline reads new text files, saves user name from a text file into record field text, then uses that value in HTTP client stage to make
a call to Twitch API. After that, stage Expression evaluator (named Cast Date) is used to enrich record with API response with field captured_at, which contains parsed times tamp value of the Date field of the response,
and to extract user name and stream_id from nested field of the response to root of the field.
In terms of SDC expressions, flattening looks as follows:
- Field Expression contains code
${record:value('/result/users[0]/_id')}; - Output field is
/stream_id.
Originally, Date field contains date time value in the following format Sun, 08 Apr 2018 11:45:57 GMT. Code used to parse this date into SDC date:
${time:createDateFromStringTZ(record:value('/header/Date'), 'Etc/GMT-1', 'EEE, dd MMM yyyy HH:mm:ss')}
Stages JDBC Producer (named Postgresql local) and Local FS (named Save to FS) are destination stages. JDBC Producer stage contains JDBC connection string, schema, and table names.
Database, schema, and table should exist before pipeline is run.
To properly save data into table, JDBC Producer stage contains Field to Column Mapping, which is used to map fields of SDC records to columns in the table.
In this case, fields /name, /stream_id, /captured_at were mapped to columns with the same names in the Postgresql database.
Fields, which are not in this mapping (and do not match column names in the table), are ignored and do not raise errors.
Stage Local FS is used to save SDC records into files on a local file system. The stage is configured to save SDC records into JSON format (multiple JSON objects per file).
Fetching data about streams
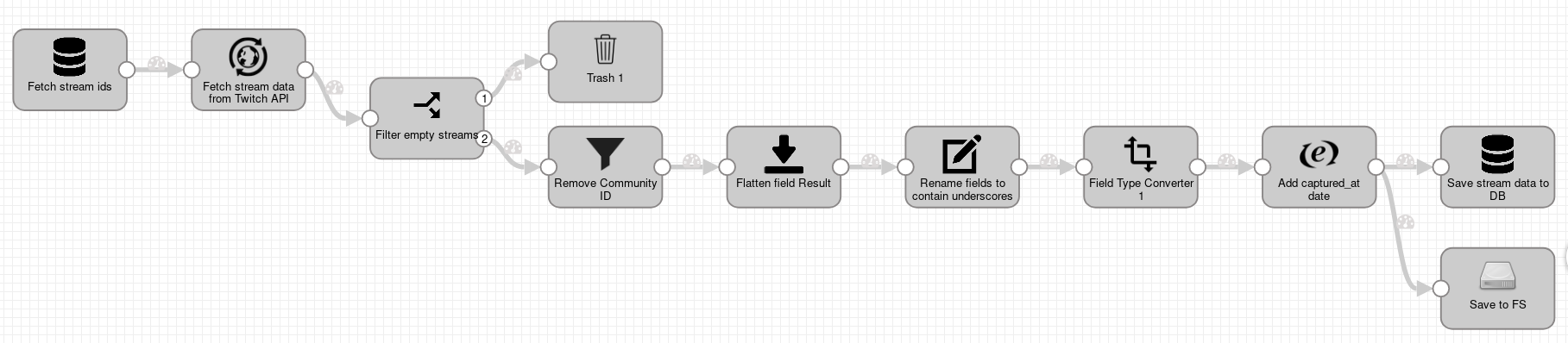
Pipeline to fetch data about streams starts with a query that selects stream_ids from a PostgreSQL table (stage JDBC Query Consumer), which was populated in the previous pipeline.
This SQL query is executed every 2 minutes. This means that even though the pipeline is running continuously, the input appears every two minutes.
For each saved stream_id stage HTTP Client (name Fetch stream data from Twitch API) executes HTTP query to obtain data about current state of the stream.
Next step (Filter empty streams) conditionally selects to where SDC records will be directed next. If a stream is not active, then corresponding SDC record will be discarded.
If a stream is active, then SDC record is directed to output number 2 to be transformed in other SDC stages.
Stage Field remover (named Remove Community ID) is used to remove unwanted fields from SDC record. Initially it was set up to remove community ids from SDC records,
but later was extended to also remove links to image previews and profile banners.
Next stage Field flattener (named Flatten field Result) is used to flatten nested data (to have records where all fields are under root
and there are no nested fields). Following stage Field renamer (named Rename fields to contain underscores) is used to rename fields to have shorter names (from /'result.stream.delay' to /delay) or
to use underscore as a delimiter instead of dot.
One of the record fields is average_fps, which sometimes contains integer value and sometimes floating point value. Stage Field Type Converter is used to force field average_fps to be casted to float.
Remaining stages Expression Evaluator (used to parse datetime values from strings), JDBC Producer and Local FS are similar to stages in the previous data pipeline.
Fetching data about games on Twitch
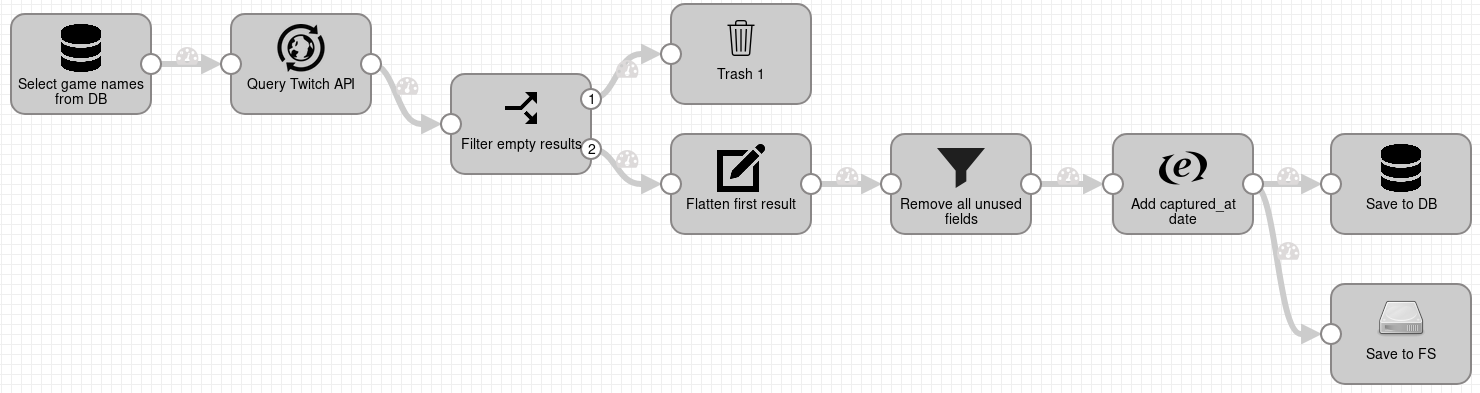
Pipeline that fetches data about games on Twitch looks very similar to the pipeline that fetches data about streams: it starts with a stage JDBC Query Consumer, which (every 5 minutes) executes a SQL query to select unique game names from last 5 minutes,
then for each game name makes a HTTP request to Twitch API to find a game by name. Twitch API might return array with multiple results, we assume that first result is the correct one.
Stage Field Renamer (named Flatten first result) renames nested fields to be directly under root. Next stage Field Remover (named Remove all unused fields) is configured to only keep
fields /giantbomb_id, /_id, /name, /popularity. All other fields will be removed. The rest of the pipeline adds a new time stamp field /captured_at to records and
saves records to PostgreSQL database and into files on local file system.
Fetching data about games from Giantbomb
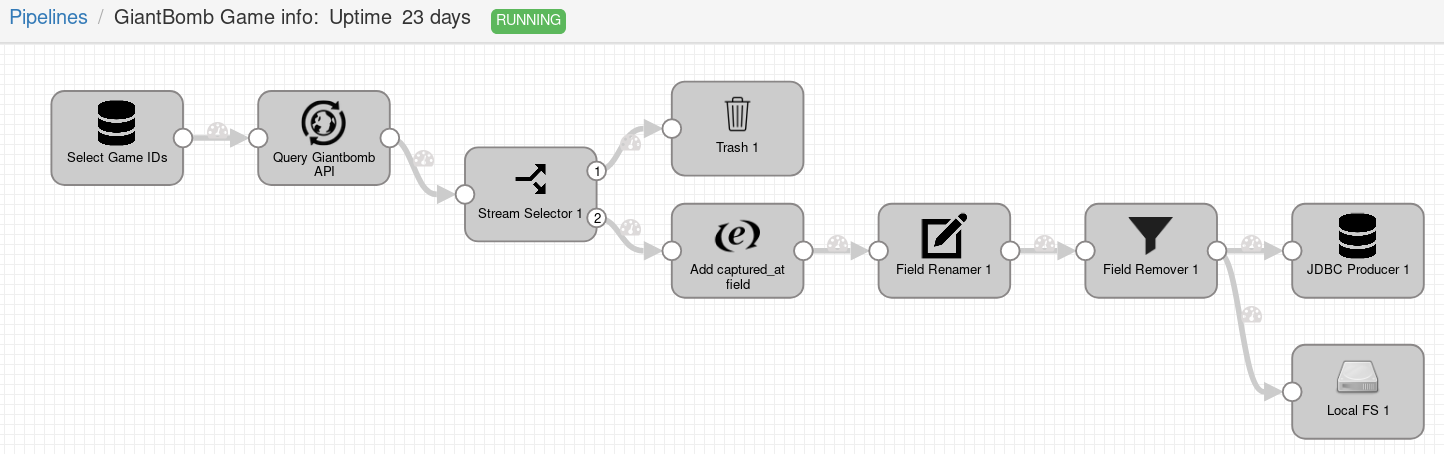
The pipeline that fetches data about games from Giant Bomb API follows the same pattern as previous pipelines that fetch data from Twitch API:
-
execute SQL query to get data from a database;
-
make a query to Giant Bomb API;
-
filter responses;
-
move fields from nested fields to be directly under root (flatten fields);
-
remove unwanted fields and enrich records with time stamp
captured_at; -
save data to PostgreSQL database and to JSON files on local file system.
Encountered problems
Time zones
Dealing with time zones became a common problem in Software Development. It was difficult to compare value of a parsed date time field in SDC record and a string with time stamp from HTTP response. The issue is that original string contains a date in GMT time zone, parsed value was represented in local time zone. It was a matter of finding a correct offset when parsing a string with date. Probably, it would be a good idea to run system, SDC, and PostgreSQL in UTC time zone to avoid confusion.
LZ4 Compression
Stage Local FS, which saves data to local files, was initially set up to
compress output files with LZ4 compression. One day later I have decided to try to decompress those LZ4 files and failed.
On Linux distribution Lxle 16.04.3 (based on Ubuntu 16.04) and Fedora 27 command-line command lz4
failed to decompress those files with error:
Error 44 : Unrecognized header : file cannot be decoded
After this compression setting has been changed to GZIP and that worked well.
Extra data in saved files
Data pipeline that converts Twitch names to Twitch IDs does not contain stages that remove unwanted fields. This does not make any problems for the stage that saves data to PostgreSQL, because only mapped fields are considered and rest are ignored. For the stage that saves SDC records into files this means that the whole SDC record is saved into a file. In this case, it means that saved JSON would contain data from a text file, added fields, and the whole HTTP response.
Positive things about SDC
- Errors in stages do not stop the whole pipeline.
- When a pipeline fails (in mentioned pipelines errors were due to DNS errors: address for HTTP requests could not be resolved) it does not affect the whole system.
- Exported pipeline definitions are saved as JSON files and could be easily saved to git
and
git diffwould show meaningful results. - Pipeline preview. This is a great feature for exploring data as it flows through a pipeline and for debugging purposes.
Refactoring
Twitch API pipelines that fetch data for streams and games were made separate to
avoid excessive requests to Twitch API. When several streamers are playing the same
game at the same time, then it makes sense to make only one request to fetch data about a game,
instead of making a request for each live stream.
While browsing through stages library, a stage that might help solving duplicated requests problem
was spotted: Record Deduplicator. Using this stage two pipelines that fetch data about Twitch
streams and twitch games were merged into a new pipeline.
In the refactored pipeline stage Record deduplicator (named Deduplicate game names) was set to
deduplicate record fields /game in the last 180 seconds (parameter Time to Compare).
This pipeline has been working for several days instead of two previous pipelines without any problems.
Results of running data pipelines with SDC for 1 month
-
Size of the log file: 139 MB
-
Number of crashes: 0
-
Number of Twitch channels that were observed: 20
-
Number of events captured for Twitch streams: 83534
-
Number of events captured for Twitch games: 32224
-
Number of records saved for Giant bomb games: 555
Conclusion
We have implemented several data pipelines that interact with Twitch API to obtain data about streams and streamed games, and with Giant bomb API to fetch data about games. Those data pipelines were implemented using product Data Collector from StreamSets. SDC provided all necessary components to implement designed pipelines: JDBC connection, HTTP client, component to interact with local file system, components to transform data. Apart from used components SDC provides a wide range of other components to interact with HDFS, Kafka, Hive, Amazon S3, Azure, Redis and more.
Extensive documentation and good UI helped with learning how to develop pipelines with SDC. Feature “Pipeline preview” was used extensively to explore data as it flows through a pipeline and to debug them.
Errors that appeared in one month of running SDC were related to network and
they affected particular stages (only HTTP Client) or whole pipelines (when
address of Twitch API could not be resolved), but never stopped the whole system.
The fact that SDC have not crashed even once in one month makes SDC a good tool
to our use case when data is streamed and can be captured only “now or never”, meaning
that if data was not captured in any moment then it is gone forever.
Definition of a pipeline can be saved into a JSON file and save into version control. The only downside is that JSON files contain positions of UI elements and if position changed then it will be shown in Git as a change.
SDC is an open source project with source code hosted on GitHub and for installation StreamSets offers several options from using source code to a docker container.
We have used the source code option and the setup was almost non-existent (extract archive and start a script).
Those data pipelines were running on an old laptop powered with CPU Intel SU2300 (2 cores, 1.2 GHz) and 3 GB RAM using default configuration of SDC.
Use of acquired data
Acquired data allows to answer some questions about streams, like which channel was online the most in some period? or Which channel had the highest stream steak?
To compute which channels were online the most, we assume that number of captured
events can be used to compare duration of time a channel was online.
Running a simple query in psql yields a result that channels “burkeblack”, “nuke73”, and
“lirik” were most online.
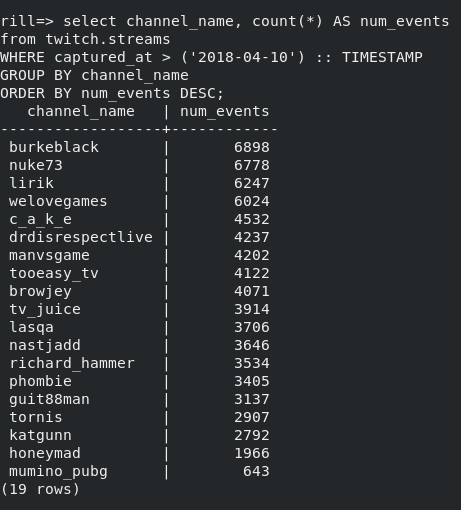
Figure. Channels by online time
Interesting observation is that 20 channels were added to be observed, but only 19 channels were returned by this SQL query. Names of channels were added in course of several days and 2018-04-10 is the first full day when no more channels were added, but one channel last streamed on 2018-04-09 and no more during the run of data pipelines.
Problem of finding a maximal streaming streak for channels is more difficult.
A post in Pivotal Engineering blog
described a similar problem in relation to trail rides.
Results of adopting their SQL query to our use case shows that “lirik” had a streaming
streak of 20 days out of 30 days observed. For this query only live streams were considered.
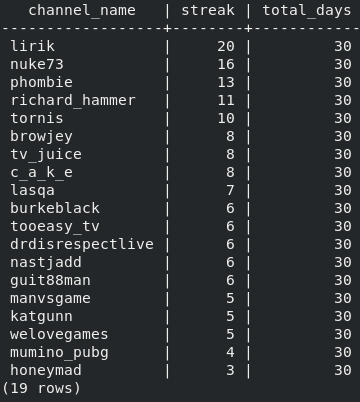
Figure. Channels by streaming streak
Those are examples of an ad hoc analysis with psql. To bring analysis to the next
level with visualizations and an ability to
share them with other people, there are plenty of tools. For example, open-source software
Apache superset and Metabase.