For the last two years I have been fetching data from Twitch API using StreamSets Data Collector and over the course of these two years Twitch API pipelines were scheduled in various ways: JDBC Query Consumer, Cron script, Orchestration pipelines.
Scheduling with JDBC Query Consumer
First versions of Twitch API pipelines were scheduled with Data Collector built-in JDBC Query Consumer. List of channels was stored in PostgreSQL database and SQL query was set to be executed on pre-defined interval using property “Query Interval” of JDBC Query Consumer.
Calls to Twitch API were handled with HTTP Client. In the first versions of the pipeline, each Twitch channel lookup generated one API call and in later versions SQL query was changed to generate a comma-delimited string of at most 100 channel IDs to perform a bulk lookup (up to 100 channels in one API call).
This setup does not scale well in terms of number of Twitch channels tracked and time to manually maintain the list of channels in the database.
Next idea was to use HTTP Client Origin to consume all online streams without providing a list of channel ids.
Scheduling with Cron
Switch to consuming all data about online channels from Twitch API using HTTP Client Origin led to increase in number of events captured and deprecation of custom channels list. But also introduced a serious problem: the pipeline could run only once.
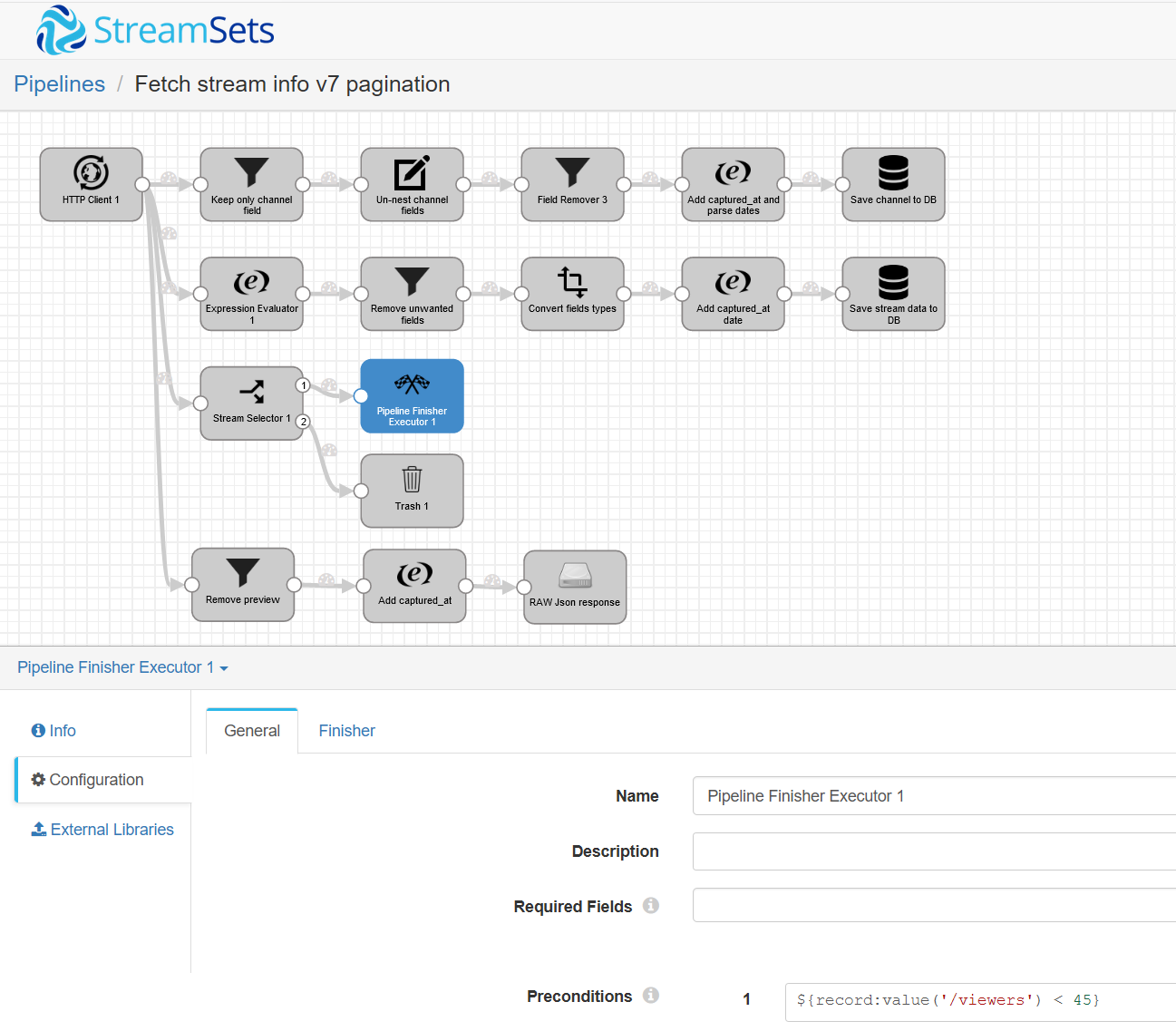
Figure. StreamSets Data collector pipeline with Pipeline finisher Stage
The StreamSets pipeline was set to finish if there were records with the value of “viewers” less than 45. Once pipeline finished an external command is needed to start the pipeline again. Streamsets DataCollector provides REST API to interact with the instance. For purposes of restarting a stopped pipeline, two operations are relevant: list all pipelines (v1/pipelines/status) and start a pipeline (/v1/pipeline/{pipelineId}/start).
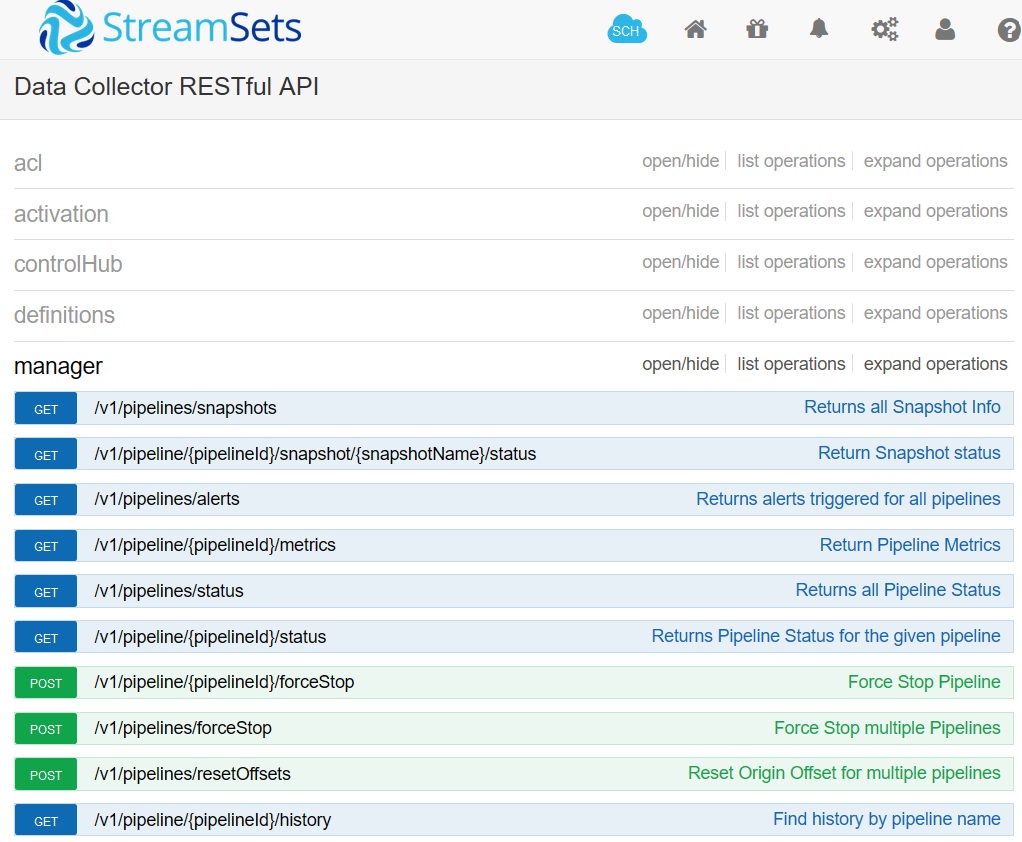
Figure. StreamSets Data collector REST API
Bash script was written to start a finished pipeline. Bash script takes SDC Pipeline ID (I have provided only unique enough part of PipelineID) and assumes that SDC username and SDC password are stored in environment variables SDC_USER and SDC_PASS respectively. Only pipelines in state FINISHED are restarted by the script, otherwise successful manual run is required (for example, after pipeline is edited).
#!/bin/bash
SRV="sdc"
PIPELINES_URL="http://$SRV:18630/rest/v1/pipelines/status"
URL="http://$SRV:18630/rest/v1/pipeline"
#fetch sdc pipelineId based on part of the pipeline name
pipeline_id=$(curl --netrc-file <(cat <<<"machine $SRV login $SDC_USER password $SDC_PASS") "$PIPELINES_URL" -H "X-Requested-By:sdc" \
| jq -r --arg PIPELINE_NAME "$SDC_PIPELINE_NAME" '[.[keys[] | select(contains($PIPELINE_NAME))]]' \
| jq ".[0].pipelineId" \
| tr -d '"' )
# check if the pipeline was found
if [ $pipeline_id = null ];
then exit 1;
fi
# start sdc pipeline
curl --netrc-file <(cat <<<"machine $SRV login $SDC_USER password $SDC_PASS") "$URL/$pipeline_id/status" -H "X-Requested-By:sdc" \
| jq ".status" \
| tr -d '"' \
| { read a; if [ "$a" = 'FINISHED' ]; then curl --netrc-file <(cat <<<"machine $SRV login $SDC_USER password $SDC_PASS") "$URL/$pipeline_id/start" -H "X-Requested-By:sdc" -X POST ; else echo "running"; fi }
Streamsets Data Collector instance was running in a docker container, so this script was also containerized (the same way as we learned before Background processes in Docker). Eventually, two pipelines were using this cron based scheduling.
Data Collector Orchestration pipelines
In version 3.15.0 StreamSets added Orchestration pipelines to Data collector. This new pipeline type cen be used to create workflows from other Data Collector pipelines. This means that cron based scheduling can be replaced with an Orchestration pipeline and my pipelines that called one Twitch API endpoint after another can be broken down into smaller pipelines. The feature was put to test by developing an orchestration pipeline that connects two other Data Collector pipelines:
- first pipeline that fetches Games data from Twitch API V5, extracts Giantbomb Game IDs, saves them to a file
- and the second pipeline that reads Giantbomb Game IDs from the file and queries Giantbomb HTTP API to collect more information about games.
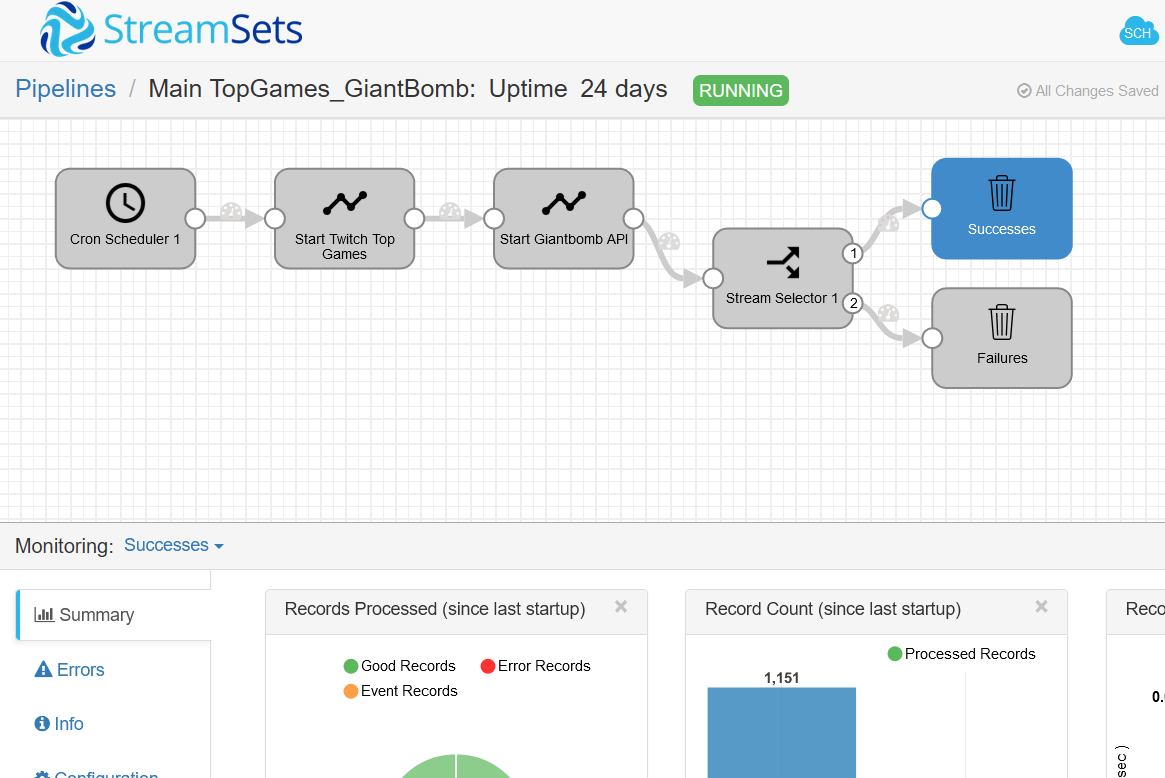
Figure. StreamSets Data collector Orchestration pipeline
Nice feature of the Orchestration pipelines is that Runtime parameters can be passed down to orchestrated pipelines to customize them. For example, both of our orchestrated pipelines have a parameter that stores a path to a directory where the file with extracted Giantbomb IDs is stored.
The Last Data collector
Latest version of Twitch API, called Helix, introduced changes to pagination in the API endpoints. If Twitch API V5 used offset-based pagination, which is supported by StreamsSets Data Collector, Helix uses cursor-based pagination, which is not supported. This means that Data Collector is not compatible with Helix endpoints when more than one page of data needs to be fetched.
To fetch data from Twitch Helix API, I have written simple Python scripts that query API endpoints and save responses in JSON format.